La TA "à parité" avec l'humain ? Ca se discute.
Posted on Mer 30 sep 2020 in Machine Translation
La parité est un sujet délicat lorsqu'on s'intéresse à l'égalité entre genres. La parité qui m'intéresse ici n'est pas moins délicate à évaluer, il s'agit de celle entre l'humain et la machine, que je vais aborder par le prisme de la traduction automatique (TA).
À intervalles réguliers, on entend que grâce aux progrès de l'intelligence artificielle, la machine est maintenant "à parité" (ou presque) avec l'humain dans l'accomplissement de tâches de plus en plus complexes, comme la transcription vocale de parole conversationnelle, ou la transcription vocale dans le domaine biomédical. La traduction automatique n'est pas de reste et l'avènement de systèmes de TA égalant l'humain, annoncée dans cet article de Google, est proclamée dans plusieurs travaux récents, dont l'un publié cette année dans la revue Nature (Popel et al, 2020), ce qui ne manquera pas de donner du poids à cette affirmation.
Pourquoi faut-il prendre de telles annonces avec des pincettes ? Principalement pour trois raisons, qui sont analysées en détail dans une série de travaux ((Toral et al, 2018);(Toral, 2019)) , le dernier de la liste en dressant une synthèse très claire. Avant de résumer leurs arguments, commençons par rappeler comment les évaluations de la TA sont menées aujourd'hui au sein de la communauté - en particulier dans le cadre des campagnes d'évaluations annuelles réalisées sous l'égide de la Conférence sur la Traduction Automatique.
Evaluer les traductions automatiques
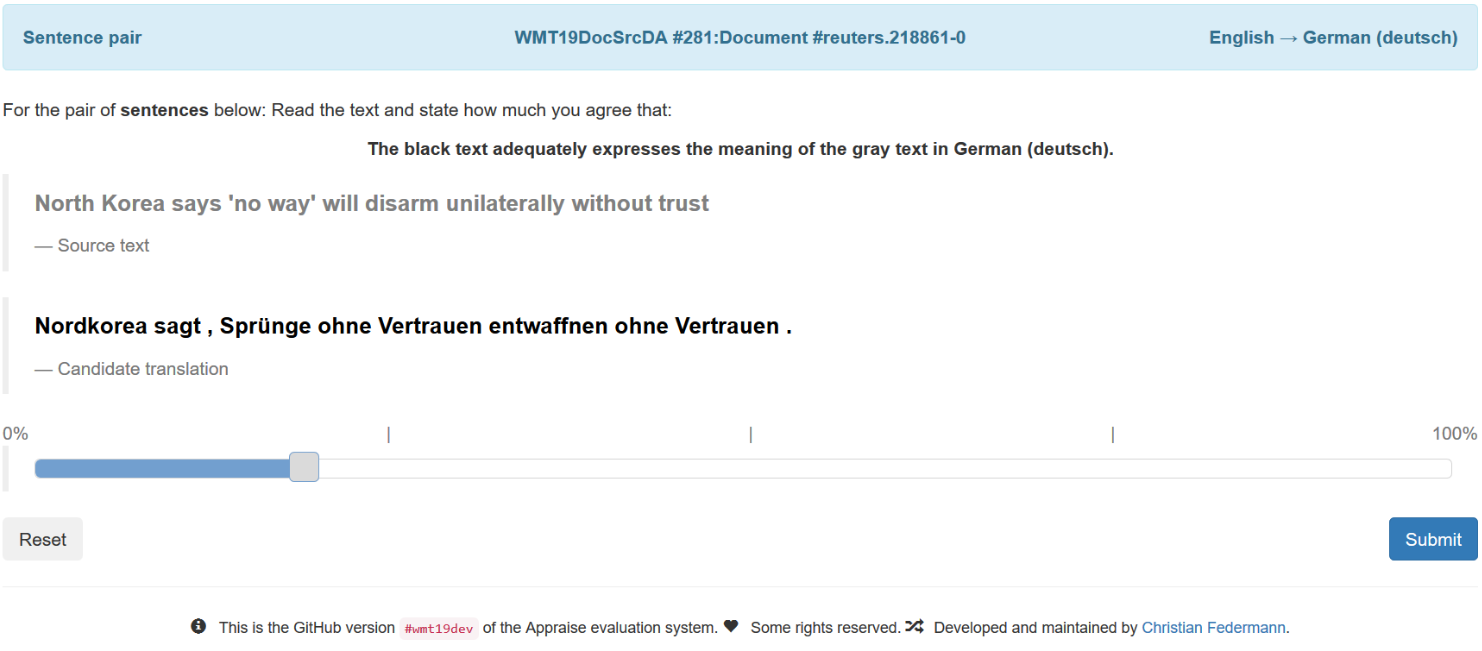
Si les métriques automatiques (BLEU, NIST ou Meteor) ont été utilisées pour les premières campagnes d'évaluation, elles ont été rapidement abandonnées au profit d'évaluations manuelles. La méthode qui s'est progressivement imposée consiste ainsi à demander à des juges humains d'attribuer une valeur de 1 à 100 à exemples de traductions automatiques. Pour guider ce jugement, on leur présente également une traduction de référence réalisée par un humain, ainsi qu'une consigne simple "Sur une échelle de 1 à 100, dire à quel point vous êtes d'accord avec l'affirmation que le texte en noir (la traduction) exprime le sens du texte grisé (la traduction de référence)". Cette tâche est très simple à réaliser et ne demande pas de compétence particulière en langue source. Elle permet, par aggrégation (et normalisation) de multiples évaluations réalisées indépendamment par de multiples évaluateurs, de donner une note globale à chaque système et ainsi de les ordonner du meilleur au pire. Une variante consiste à présenter la phrase source à la place de la traduction de référence; elle requiert des évaluateurs bilingues et est donc plus difficile à mettre en oeuvre. L'interface d'évaluation pour des évaluateurs bilingues est reproduite ci-dessous (figure tirée de (Barrault et al, 2019)).
Dans les premières expériences dont il est question ici, qui portent sur les paires de langues anglais-chinois (Hassan et al, 2018), et tchèque-anglais (Bojar et al, 2018), l'affirmation de parité de la machine avec l'humain a été obtenue en comparant avec cette méthode le "score" global d'un traducteur ou d'une équipe de traducteurs avec une TA et en n'observant que ces scores n'étaient pas significativement différents.[^1]
Du point de vue méthodologique, les mesures que ces travaux mettent en exergue sont conformes aux pratiques de la communauté. Elles ne permettent pas de conclure à la "parité" pour autant, pour au moins trois raisons qui sont longuement discutées dans (Läubli et al, 2020) et qui ont trait aux détails du protocole expérimental.
L'évaluation de phrases isolées
Les systèmes de TA, dans leur majorité, traduisent des phrases isolées. Est-il pour autant raisonnable de demander aux juges d'évaluer des phrases isolées ? La réponse est plutôt non, et les erreurs de la machine apparaissent plus clairement quand les évaluateurs ont accès aux phrases qui précèdent et suivent la phrase évaluée, ce qui conduit à diminuer leur score global. Ce contexte supplémentaire permet par exemple de repérer des des fautes d'accord, des incohérences, etc, qui ne peuvent être détectées à partir d'une phrase isolée. Dans la mesure où l'activité de traducteurs humains ne consiste qu'exceptionnellement à traduire des phrases isolées, pour atteindre la "parité", il faudra que les productions de la machine soit indiscernable d'une traduction humaine pour '''des documents complets'''. Notons qu'il n'existe pas pour l'instant de méthode pour comparer efficacement des traductions de documents entiers - c'est un sujet qui gagne de l'importance au sein de la communauté, en atteste la proposition récente de (Läubli et al, 2018); en revanche l'idée d'intégrer un contexte discursif local aux phrases analysées a fait son chemin. Elle est utilisée dans la dernière campagne d'évaluation organisée dans le cadre de la conférence WMT 2019 et documentée dans (Barrault et al, 2019).
En pratique, chaque phrase à évaluer est présentée en faisant également figurer les phrases qui la précèdent et la suivent immédiatement; les phrases sont évaluées dans l'ordre de leur succession dans le texte[^2]. Avec cet ajustement, la "parité avec l'humain" n'est atteinte que pour un seul système et une direction de traduction, alors que l'évaluation sans contexte laisserait penser que trois directions de traduction (anglais-allemand dans les deux directions, russe vers anglais) sont concernées.
Les traductions de référence
Dans le protocole décrit ci-dessus, les évaluateurs ont accès à des traductions de référence qui leur permettent d'apprécier la qualité des traductions produites. Dans le cadre usuel des évaluations de la TA, ces références sont souvent produites par des locuteurs compétents de S et de T, mais rarement par des locuteurs natifs. Pourtant il apparait, si l'on améliore la qualité de ces références, que les évaluateurs se montrent plus critiques avec les traductions de la machine, comme si en augmentant le contraste, on mettait mieux en lumière les approximations de la TA. Pour pouvoir conclure à la parité, il faudrait comparer les productions de la machine à des traductions humaines dont la qualité est contrôlée. Traduire est un métier, et bien traduire n'est pas donné à tout locuteur, même bilingue.
Paradoxalement, l'usage d'un protocole d'évaluation "monolingue" semble jouer en défaveur des traductions humaines. Dans cette configuration, les traductions ressemblant à la référence sont jugées bonnes - indépendemment de leur qualité intrinsèque -, celles qui s'en éloignent sont inversement jugées mauvaise. Or il existe entre traducteurs différents une variabilité telle que la seconde situation est, dans les faits, assez commune, et conduit à une dégradation des évaluations des traductions humaines. Ce biais est en particulier documenté dans (Bentivogli et al, 2018) (Toral, 2019).
Le choix des évaluateurs
Pour évaluer des traductions entre les langues S et T, il faut des évaluateurs capables de le faire. Est-ce donné à tout locuteur de la langue T ? Des travaux antérieurs, conduits avec des systèmes statistiques, tendent à montrer que oui, ou plus précisément qu'en accumulant des avis "profanes" sur la qualité des traductions, on obtient les mêmes conclusions que si l'on collecte des avis "experts" (d'experts en traduction). Il apparait pourtant que pour les systèmes neuronaux -- dont la qualité apparente (la fluidité de la langue cible), ce résultat n'est plus valable: lorsque l'on consulte de "vrais" experts (par exemple des traducteurs professionnels), ils se montrent en moyenne plus critiques que les non-experts pour juger les traductions automatique (Castilho et al, 2017). '''Première recommandation:''' il faut des experts traducteurs (encore mieux, des enseignants dans les cursus de traduction) pour juger si oui ou non les traducteurs automatiques les surpassent (comme il faut un champion du monde de Go, et pas un amateur, pour faire reconnaître la supériorité de la machine à ce jeu).
Le choix de la tâche
Quels sont les textes traduits ?
Choix de la source et "traductionnais"[^3]
En dépit de leurs faiblesses méthodologiques, il est important de relever que les travaux cités (à voir) avaient pris soin d'éviter un écueil bien documenté, qui a trait à la sélection des phrases à traduire. Un usage ancien consiste à évaluer les deux directions S->T et T->S en parallèle, à partir d'un lot de documents de référence constitué pour partie de N documents écrits en S (et traduits en T), et pour l'autre partie, de M documents rédigés en T (et traduits en S). Cette pratique a pour effet de maximiser la rentabilité des traductions humaines, puisque l'on dispose ainsi de M+N documents parallèles pour évaluer chaque direction de traduction. Le problème est qu'une partie des phrases sources utilisées pour évaluer la qualité de la traduction de S vers T sont en fait des traductions (humaines) de T vers S, et sont en fait bien plus faciles à (re)traduire automatiquement que des vraies phrases sources initialement produites en langue S. La raison est que la langue des traductions (le traductionnais) diffère de la "vraie" langue source de multiples manière: lexique simplifié, structures syntaxiques calquées sur la langue source, etc - autant de traits qui la rend plus facile à retraduire. Une analyse de ce phénomène est donné dans (Toral et al, 2018), à partir des données (Hassan et al, 2018), qui évalue la différence de qualité de traduction entre les deux types de phrases à au moins 5 %.
L'étude de Nature
L'étude publié dans Nature réutilise les données de l'évaluation de 2018 pour la direction anglais vers tchèque pour le système de traduction CUBBITT et cherche à éviter certains des biais listés ci-dessus. En particulier, elle utilise une évaluation en contexte et a recours à un groupe d'évaluateurs experts, dont les jugements complètent ceux des évaluateurs profanes. Elle se distingue par une échelle réduite (de 1 à 10), et par l'évaluation séparée de la fluidité (fluency) du texte cible généré, et de son adéquation (adequacy) au texte source[^4]. Ses résultats corroborent en fait largement les observations précédentes: évaluer en contexte permet de mieux distinguer les failles de la traduction automatique; les évaluateurs professionnels sont plus critiques à son égard. Et contrairement à ce qu'annonce le titre (''Transforming machine translation: a deep learning system reaches news translation quality comparable to human professionals") de l'article, la traduction automatique est en fait jugée de moindre qualité que la traduction humaine: "CUBBITT outperformed the human reference in adequacy, whereas the reference was scored better in fluency and overall quality (Supplementary Fig. 7)." Elle contient toutefois plusieurs résultats complémentaires intéressants, notamment (a) la difficulté pour des humains à distinguer les traductions automatiques des traductions humaines; (b) la supériorité de la TA en matière de préservation du sens ("(...) CUBBITT significantly out-performed professional-agency English-to-Czech News translation in preserving text meaning (translation adequacy). While human translation is still rated as more fluent (...),). Cette observation va à l'encontre l'avis général que la TA neuronale excelle à produire des sorties grammaticalement correctes, au détriment parfois de la préservation du sens.
Parité ou pas parité
Les progrès de la traduction automatique sont réels, tangibles et transforment le secteur de la traduction professionnelle; ils se diffiusent rapidement et font naitre des usages nouveaux -- par exemple pour l'apprentissage des langues --, gagnant chaque jour de nouveaux utilisateurs à ces technologies. C'est bien le principal, et la question de la parité avec l'humain semble bien secondaire au fond -- même si elle permet des annonces triomphales. Contrairement à certaines capacités cognitives universellement répandues, et que la machine pourrait un jour atteindre ou dépasser, la notion de "performance humaine" en traduction de veut pas dire grand'chose. Il existe d'excellents humains traducteurs, il en existe aussi de mauvais, mais l'humain qui est de loin le plus répandu est le non-traducteur, qui est donc loin d'être à parité avec des modèles qui ont analysé, pour leur apprentissage, des centaines de millions de phrases parallèles. Par ailleurs, l'exercice de la traduction présuppose toujours un récepteur, pour les besoins duquel on traduit, à chaque fois différemment. Faute, au fond, de pouvoir dire avec quel(s) humain(s), et pour quels usages, on compare la TA, les débats oiseaux sur la parité restent condamnés à tourner en rond.
[1] Les définitions proposées par Hassan et al., (2018) sont les suivantes: * Definition 1.If a bilingual human judges the quality of a candidate translation produced by a human to be equivalent to one produced by a machine, then the machine has achieved human parity. * Definition 2. If there is no statistically significant difference between human quality scores for a test set of candidate translations from a machine translation system and the scores for the corresponding human translations then the machine has achieved human parity.
[2] La taille du contexte discursif à présenter pour réaliser une évaluation juste est discutée récemment dans Castilho et al, 2020.
[3] Je traduis ainsi l'anglais "translationese", qui désigne la langue des documents traduits. Le translationnais diffère de la langue cible de la traduction sous de multiples aspects, qui sont décrits et analysés en particulier par Mona Baker.
[4] L'utilisation de notations séparées pour la fluidité et la préservation du sens est un retour à une pratique ancienne, mais délaissée. Il semblait acquis, au moins pour la génération précédente des systèmes, que ces deux dimensions étaient très liées, et difficiles à évaluer séparément. En particulier, évaluer l'adéquation d'un texte incompréhensible relève souvent de la gageure.